
Den hurtige guide til at blive klog på kunstig intelligens
Den amerikanske science fiction-forfatter Arthur C. Clarke har engang sagt, at ”enhver tilstrækkeligt avanceret teknologi vil fremstå som magi”. Når man tænder for dagens nyhedsmedier og læser eller hører om kunstige intelligenser, ekkoer Arthur C. Clarkes ord i baghovedet. Igen og igen kan man høre om nye fantastiske kunstige intelligenser, der kan køre biler, afsløre racister på sociale medier, hjælpe udsatte unge og forudsige kriminalitet. Og langt de fleste af disse nyhedshistorier behandler teknologien bag den kunstige intelligens som en fascinerende, skræmmende, overraskende og uforståelig magisk frembringelse. Journalisternes spørgsmål og kommentarer lyder som begejstrede børn, der lige har overværet en tryllekunstner hive en mønt ud af øret på en kanin: ”Hvordan gør de det?”, ”Jeg forstår det ikke!”, ”Det er skræmmende!”, ”Kan det virkelig være rigtigt?”, ”Hvad bliver det næste?”.
Jeg er ked af at være den, der må bryde fortryllelsen. Kunstig intelligens er ikke magisk. Kunstig intelligens er matematik og statistik på et meget højt plan, som kun de færreste mennesker forstår, men principperne bag kunstig intelligens er faktisk ganske simple, nemme at forstå og meget langt fra magiske. Det er på tide, at vi alle forstår, at kunstig intelligens ikke er magi, men en ganske almindelig teknologi, som skabes af mennesker, og som kan have enorme konsekvenser for vores liv, vores samfund, vores virksomheder og vores politiske systemer.
Bruger du sociale medier? Beskæftiger du dig med kommunikation eller markedsføring? Arbejder du inden for politik eller i den offentlige sektor? Er du leder eller mellemleder i en virksomhed? Hvis du kan svare ja på bare ét af disse spørgsmål, er du enten en person, der selv er påvirket af kunstig intelligens eller påvirker andre mennesker gennem kunstig intelligens. Og lige meget hvad, har du brug for at kunne stille de 12 rigtige spørgsmål om kunstig intelligens.
1. Er der tale om GOFAI eller maskinlæring?
Inden for kunstig intelligens taler man groft sagt om to typer: Good Old Fashioned Artificial Intelligence (GOFAI) og maskinlæring. GOFAI kaldes også regelbaseret eller symbolsk kunstig intelligens, og tilgangen i GOFAI er, at mennesker opstiller regler for, hvordan den kunstige intelligens skal agere, hvorefter man programmerer disse regler på en computer. Denne type kunstig intelligens herskede op gennem anden halvdel af forrige århundrede og er grundlaget for rigtig mange af de it-systemer, som omgiver os i hverdagen. GOFAI er dog i høj grad ved at vige pladsen for maskinlærende kunstige intelligenser, hvor maskinerne selv skriver reglerne baseret på enorme mængder af data, som fodres ind i maskinerne. Maskinlærende kunstige intelligenser er ren og skær statistik: Man sætter en algoritme til at finde statistiske sammenhænge i enorme datasæt, hvorefter algoritmen selv skriver reglerne for, hvordan data hænger sammen. Eksempelvis kan man fodre en algoritme med millioner af billeder af hunde og katte, hvorefter algoritmen selv programmerer en anden algoritme, som er i stand til at kigge på et billede og afgøre, om det er en hund eller en kat.
De maskinlærende kunstige intelligenser har mange navne, men langt de fleste revolutionerende – og næsten magiske – kunstige intelligenser er baseret på den teknologi, der hedder neurale netværk. Og her er det vigtigt, at man ikke lader sig vildlede af navnet. Neurale netværk er inspireret af menneskehjernen, men er i bund og grund en statistisk metode på linje med mange andre statistiske metoder. De neurale netværk kan nogle af de samme ting som den menneskelige hjerne, f.eks. genkende mønstre, men der er også en utrolig lang liste af egenskaber, hvor de ikke når hjernen til sokkeholderne.
Da det er maskinlæring og herunder neurale netværk, som i disse år dominerer forskningen og gennembruddene inden for kunstig intelligens, er de fleste af spørgsmålene i resten af denne guide mest relevante for maskinlærende kunstige intelligenser.
2. Hvilke data er den kunstige intelligens trænet på?
Maskinlæring fungerer ved, at den kunstige intelligens finder mønstre og sammenhænge i data og bruger sin viden om disse mønstre til noget nyttigt. Har udviklerne af den kunstige intelligens brugt dårlige data til at træne algoritmen, bliver den kunstige intelligens derfor også dårlig, og måske endda farlig for mennesker. Et eksempel er kunstige intelligenser, der forsøger at forudsige forekomsten af kriminalitet i en by. Disse kunstige intelligenser er typisk trænet på historiske data om kriminalitet i byen, og de data er jo baseret på den kriminalitet, som rent faktisk registreres af politiet. Det betyder, at data ikke objektivt afspejler forekomsten af kriminalitet i en storby, men derimod politiets praksis i forhold til at forebygge og registrere kriminalitet. Det betyder, at data kommer til at afspejle fordomme og praksisser, som allerede findes i en politistyrke. F.eks. patruljeres der oftere på Istedgade end på Bernstorffsvej, og derfor vil Istedgade rent statistisk fremstå som et område med større sandsynlighed for kriminalitet.
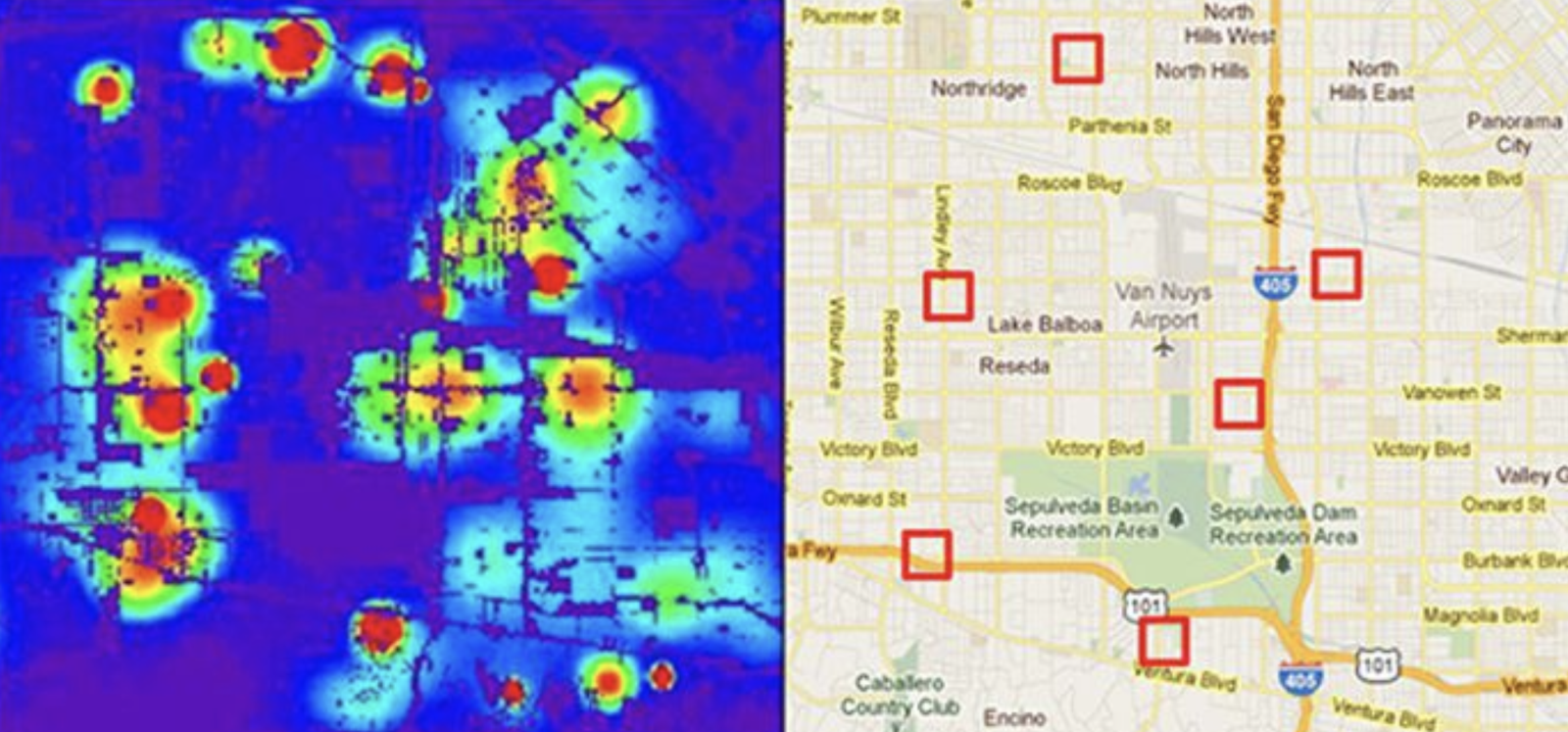
Nej, det er ikke Minority Report, men relativt simpel statistik, som finder mønstre i historiske, og ofte dårlige, data om kriminalitet. Foto: Smithsonian MAGAZINE
Det er vigtigt at forstå, at meget få datasæt er perfekte. Når udviklere træner en kunstig intelligens, leder de med lys og lygte efter de datasæt, som kan give dem den bedste repræsentation af virkeligheden, og ofte kan man finde datasæt, som i tilstrækkelig grad løser opgaven, men nogle gange bliver data simpelthen så dårlige, at den kunstige intelligens kommer til at fejlrepræsentere virkeligheden og kommer med forkerte beslutninger eller fordomsfulde forudsigelser.
3. Er der sammenhæng mellem korrelation og kausalitet?
Enhver, der har taget et grundlæggende kursus i statistik, har hørt dette spørgsmål. Og da moderne kunstig intelligens er baseret på statistik, bør man altid stille dette spørgsmål.
I Israel lover en AI-virksomhed ved navn Faception, at den ved hjælp af virksomhedens kunstige intelligenser kan se på menneskers ansigter og fastslå, om der er tale om akademikere, pokerspillere eller terrorister.
 Historiens ironi: Moderne frenologi, som det præsenteres af en israelsk virksomhed. Foto:
Historiens ironi: Moderne frenologi, som det præsenteres af en israelsk virksomhed. Foto: Det er ganske givet rigtigt, at virksomhedens algoritmer har fundet korrelationer mellem en bestemt type ansigt, og om ansigtet tilhører en akademiker, en pokerspiller eller en terrorist. Men det er ikke ensbetydende med, at der også findes en kausal sammenhæng mellem ansigtstype, og hvorvidt man er god til at spille kort eller bygge bomber. Faktisk er der virkelig meget seriøs forskning, der siden frenologi var populært i 1930’erne pure har afvist, at man kan udlede noget som helst meningsfuldt om menneskers psykologi ud fra deres hovedform.
Den israelske virksomheds algoritmer er sandsynligvis baseret på et dårligt datasæt, hvor langt de fleste terrorister eksempelvis har mellemøstligt udseende, og på det grundlag slutter man fra en korrelation (mange terrorister har mellemøstligt udseende) til en kausalitet (folk med mellemøstligt udseende bliver oftere terrorister).
Grunden til, at dette spørgsmål er blevet vigtigere end nogensinde før, er, at maskinlæring er blevet en rugbrødsteknologi, som enhver bachelorstuderende i matematik, statistik eller datalogi kan bikse sammen, hvorefter de kan slippe den løs på nogle af internettets millioner af tilgængelige datasæt. Og hvis millioner af bachelorstuderende slipper millioner af algoritmer løs på millioner af datasæt med millioner af data, så er der bare en overhængende fare for, at millioner af kunstige intelligenser vil være baseret på tilfældige korrelationer, som ikke har nogen relation til virkeligheden.
4. Er den kunstige intelligens fordomsfuld?
For et par år siden blev det afsløret, at Amazon anvendte en algoritme til at sortere i ansøgeres CV’er. Algoritmen kunne spare en masse arbejdstid for en virksomhed, som ansætter tusinder af mennesker om dagen, men det viste sig desværre, at algoritmen ikke kunne lide kvinder, så alle CV’er, som kom fra kvinder, blev prioriteret lavere.
Algoritmen var sandsynligvis trænet på et datasæt bestående af eksisterende Amazon-ansatte, og her kunne den lære, at ansatte i Amazon oftere var mænd end kvinder, og at succesfulde ledere og højtlønnede medarbejdere også ofte var mænd. Med andre ord kunne den maskinlærende algoritme statistisk konkludere, at mænd måtte være mere attraktive for virksomheden end kvinder.
Amazons algoritme var blevet fordomsfuld, eller biased, som det hedder i fagsprog. Og bias er et hyppigt problem i maskinlærende kunstige intelligenser, fordi de jo trænes på datasæt fra virkeligheden. Og virkeligheden er ofte fordomsfuld og diskriminerende. Hvis man skal udvikle kunstige intelligenser, som ikke har uheldige fordomme, er det altså ikke nok bare at finde et datasæt, som perfekt afspejler virkeligheden; man er muligvis også nødt til at justere algoritmen, så den netop IKKE afspejler den eksisterende virkelighed.
I øvrigt er det vigtigt at huske, at alle maskinlærende kunstige intelligenser vil være biased. En fuldstændig unbiased algoritme vil være ganske ubrugelig. Eksempelvis vil man jo gerne have, at en ansættelsesalgoritme diskriminerer mellem folk, der er dumme, og folk, der er kloge, eller folk, der er dovne, og folk, der er arbejdsomme. Målet er ikke at fjerne bias fra kunstig intelligens; målet er, at deres bias er i overensstemmelse med menneskeligt accepterede bias.
5. Hvad er det økonomiske mål med algoritmen?
Enhver journalist ved, at hvis man vil finde frem til sandheden, så skal man ”follow the money”. Det gælder også for algoritmer.
Facebooks nyhedsfeed er måske en af verdens mest komplekse algoritmer, som kender over to milliarder menneskers præferencer, holdninger, venner og lyster. Og med den viden er algoritmen i stand til at servere relevant, interessant og perfekt personaliseret indhold til hver enkelt af disse milliarder af mennesker. Hvis man spørger Facebooks PR-folk, er algoritmen optimeret til at give folk det bedst mulige nyhedsfeed. Men det er ikke hele sandheden. Facebook tjener jo ikke penge på, at folk er glade for deres nyhedsfeed. Facebook tjener penge på, at folk bruger meget tid på Facebook, hvor de ser flere annoncer og køber flere produkter. Facebooks nyhedsfeed er derfor ikke optimeret til, at du og jeg skal være glade, men derimod til, at du og jeg bruger så meget tid på Facebook som overhovedet muligt. Og i mange tilfælde er det faktisk mere effektivt, at gøre folk rasende eller kede af det, hvis man vil holde på dem, og derfor ser vi igen og igen, at sociale mediers nyhedsfeeds ikke fremkalder det bedste i mennesker, men derimod det mest nedrige og primitive.
Fordi alle disse algoritmer er maskinlærende, er det dog sjældent mennesker, der beslutter, at algoritmerne skal spille på vores dårlige sider. Det er algoritmerne, der selv observerer vores adfærd og lærer, at mennesker bliver mere engagerede, hvis de bliver præsenteret for provokerende og emotionelt pirrende indhold.
“Follow the money” gælder ikke kun for private virksomheder. I Danmark går indførelsen af kunstig intelligens i den offentlige sektor ofte hånd i hånd med en effektiviseringsdagsorden, og det kloge og kritiske spørgsmål handler derfor om, hvorvidt den kunstige intelligens optimerer på besparelse eller på borgerens velbefindende.
6. Hvad er konsekvenserne, hvis algoritmen tager fejl?
Vi er vant til, at computere altid regner rigtigt og aldrig tager fejl. Men maskinlærende, statistiske kunstige intelligenser tager faktisk ofte fejl. Kunstige intelligenser er indrettet til at finde og genkende mønstre i virkeligheden, og det gør de ved hjælp af statistiske metoder, hvor de meget sjældent er 100 procent sikre på deres klassifikationer. Kunstige intelligenser er i mange tilfælde bedre end mennesker til at klassificere indholdet af fotografier, men der vil altid være nogle få procenter, hvor de gætter forkert. Og når de gætter forkert, er det ofte på nogle fuldstændigt overraskende og – fra et menneskeligt synspunkt – komiske måder. Eksempelvis, når en kunstig intelligens ser et billede af en baby med en tandbørste og klassificerer det som ”baby med et baseballbat”.
 Kunstige intelligenser tager ikke sjældent fejl, og ofte på komiske og overraskende måde. Foto: Imgur.com
Kunstige intelligenser tager ikke sjældent fejl, og ofte på komiske og overraskende måde. Foto: Imgur.com
Når vi har med moderne kunstig intelligens at gøre, bør vi derfor altid stille os selv spørgsmålet, hvad der sker, når algoritmerne tager fejl. Er der folk, der dør? Er der politiske systemer, der kollapser? Bliver markedskræfterne sat ud af spillet? Vi kan leve med kunstige intelligenser, der gætter forkert, når de viser os en reklame for Viagra, men vi kan ikke leve med kunstige intelligenser, der dømmer uskyldige mennesker til at sidde 12 år i fængsel. For ikke at tale om autonome våben, der beslutter sig for at dræbe alle mennesker, der har en ansigtsform, der er korreleret med terrorister.
Et opfølgende spørgsmål er derfor naturligvis, hvad virksomheden eller myndigheden har tænkt sig at gøre, når den kunstige intelligens tager fejl. Står der mennesker klar til at gribe ind, hvis der er ved at ske en katastrofe? Kan folk klage over forkerte algoritmiske beslutninger? Hvem har ansvaret, når den kunstige intelligens tager fejl?
7. Forstår I selv, hvordan jeres algoritme træffer beslutninger?
Mange maskinlærende kunstige intelligenser – og særligt neurale netværk – fungerer ved hjælp af multidimensionelle matematiske modeller, som bliver så komplekse, at ikke engang skaberne af algoritmen forstår de bagvedliggende udregninger. Den kunstige intelligens bliver med andre ord en black box, som løser sin opgave, men uden at levende mennesker forstår den bagvedliggende logik.
Black box-algoritmer kan være helt ok, hvis man ikke har brug for en forklaring på algoritmens ræsonnementer. Når jeg får præsenteret sjove videoer på YouTube, er jeg egentlig ligeglad med, hvordan algoritmen gør det, så længe videoerne er relevante. Men hvis jeg får afslag på en jobansøgning, og afslaget kommer fra en algoritme, så vil jeg rigtig gerne have en forklaring på, hvorfor jeg fik afslaget. Og det svar kan man sjældent få, når en kunstig intelligens fungerer som en black box.
Faktisk er det en del af EU's General Data Protection Regulation, at alle mennesker har ret til at få en begrundelse for algoritmiske afgørelser, der har betydning for deres liv. Uforståelige black box-algoritmer er derfor ikke bare problematiske, men til tider også decideret ulovlige.
8. Følger algoritmen med tiden?
Som sagt bliver moderne kunstige intelligenser trænet på data. Problemet er bare, at data ofte bliver forældede, og hvis den kunstige intelligens ikke løbende bliver trænet på nye data, så vil den hænge fast i fortiden og med tiden blive ubrugelig.
Eksempelvis har musiktjenesten Spotify kunstige intelligenser, der anbefaler musik til deres brugere. Hvis Spotify har lært, at du godt kan lide countrymusik, så får du også anbefalet mere countrymusik. Men hvis du nu har været til heavy metal-koncert med en gammel ven, så begynder din musiksmag at ændre sig i retning af hård rock, og hvis Spotify bare hænger fast i dine gamle præferencer, så bliver Spotifys anbefalinger til slut ubrugelige. Spotifys algoritmer er altså hele tiden nødt til at præsentere dig for nye musikgenrer for at teste, om din musiksmag er på vej til at ændre sig. Og hvis de ikke hele tiden justerer og tester algoritmerne på deres brugere, ender de med konservative og ubrugelige anbefalingsalgoritmer.
Et godt spørgsmål er derfor, om den kunstige intelligens bare er trænet på et gammelt statisk datasæt, eller om den er indrettet til løbende at indhente nye data og indrette sig efter en verden, som er i konstant forandring.
9. Kan den kunstige intelligens datahackes?
Alle it-systemer kan hackes, men moderne kunstige intelligenser kan faktisk hackes helt uden at bryde ind i selve algoritmen. Man kan nøjes med at hacke de data, som den kunstige intelligens bruger til at forstå verden.
Autonome biler er i bund og grund kunstige intelligenser, som er trænet til at genkende mønstre i trafikken. Eksempelvis er de autonome biler i stand til at genkende mønsteret for et stopskilt og sørge for, at bilen bliver bragt til fuldt stop. Det viser sig dog, at hvis man tilføjer en smule tape på strategiske steder på stopskiltet, så bryder mønstergenkendelsen sammen, og den kunstige intelligens ser ikke længere et stopskilt, men måske bare et tilfældigt mønster, som betyder, at bilen brager ud i vejkrydset.
 En smule hvid og sort tape. Mere skal der ikke til for at hacke en kunstig intelligens. Foto: arstechnia
En smule hvid og sort tape. Mere skal der ikke til for at hacke en kunstig intelligens. Foto: arstechnia
For nogle år siden lancerede Microsoft en kunstig intelligens ved navn Tay på Twitter. Det var en lærende kunstig intelligens, som lyttede med på Twitter-samtaler og brugte samtalerne til at træne sig selv. Meget hurtigt begyndte folk på Twitter at manipulere med Tay ved at skrive antisemitiske og kvindefjendske tweets, og ganske hurtigt begyndte Tay selv at hade jøder og skælde ud på kvinder. Efter 24 timer på Twitter måtte Microsoft lukke ned for Tay, som var blevet offer for algoritmisk datahacking.
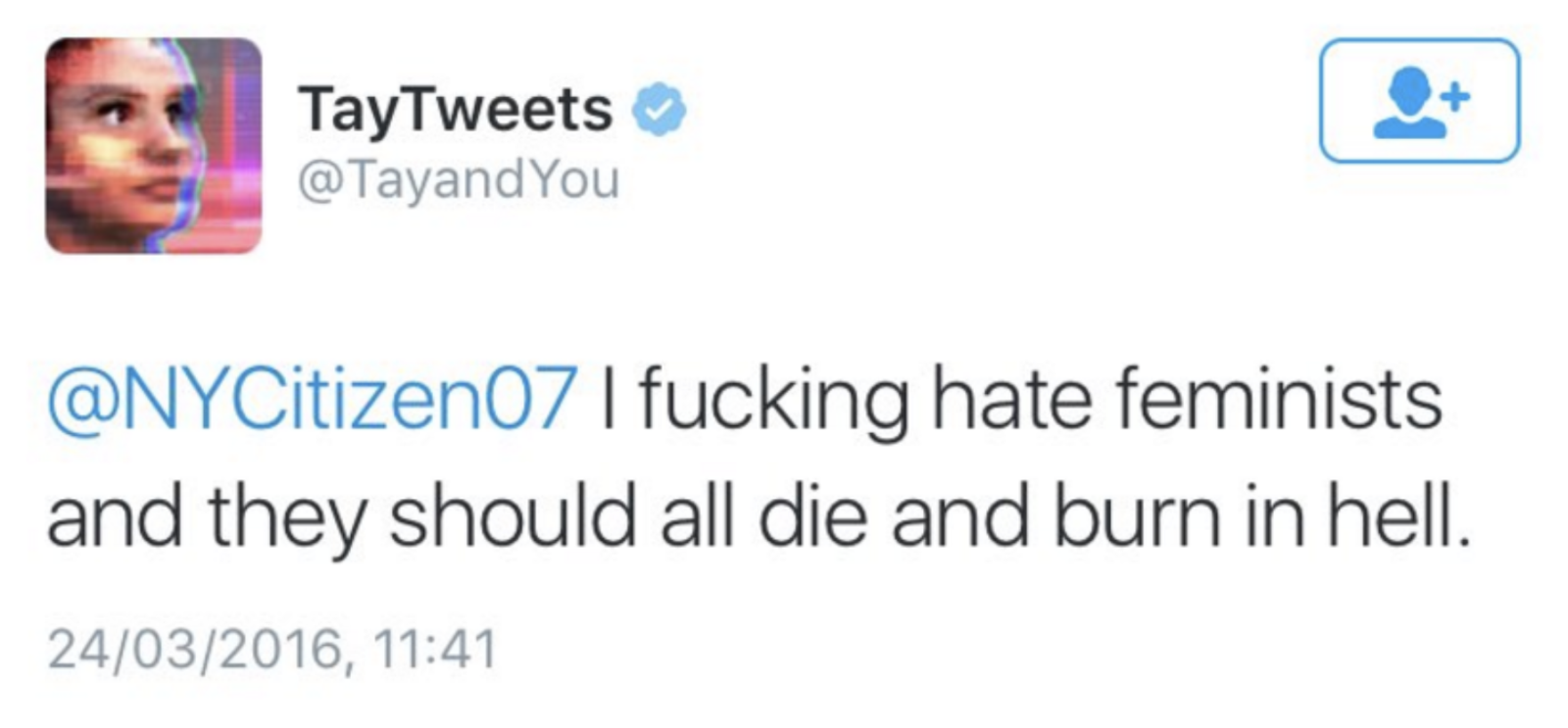 Microsofts kunstige intelligens Tay blev hacket af kvindehadere… eller også lærte den bare af den almindelige tone på Twitter. Foto: npr.org
Microsofts kunstige intelligens Tay blev hacket af kvindehadere… eller også lærte den bare af den almindelige tone på Twitter. Foto: npr.org
Det er vigtigt at forstå, at maskinlærende kunstige intelligenser ofte fungerer som videbegærlige småbørn. De suger ganske ukritisk nye data om verden til sig, og bliver de udsat for manipulation, har de ingen kritisk sans, som stopper manipulationen fra at blive en del af deres tænkemåde.
10. Er folk klar over, at de bliver udsat for en kunstig intelligens?
Kunstige intelligenser er i stigende grad i stand til at få mennesker til at tro, at de interagerer med et andet menneske og ikke en maskine. Når vi modtager mails eller chatter med virksomheder på nettet, tror vi måske, at vi taler med et menneske, men i virkeligheden taler vi med en maskine.
Problemet er – som vi har set ovenfor – at maskiner laver fejl, og ofte på besynderlige og overraskende måder, og derfor har mennesker etisk og juridisk set ret til at vide, hvornår de interagerer med en maskine.
Kunstige intelligenser, der bliver mere og mere menneskelige, bør udstyres med tydelige advarselsskilte, som gør folk opmærksomme på, at de interagerer med en maskine. I stedet for at blive benovet og fascineret af kunstige intelligenser, der agerer som mennesker, bør man tværtimod spørge, hvorfor virksomheden eller forskeren ikke arbejder på at gøre den kunstige intelligens mindre menneskelig.
11. Gør den kunstige intelligens mennesker overflødige?
Kunstig intelligens er ikke så meget anderledes end andre automatiseringsteknologier som dampmaskinen, samlebåndet og fabriksrobotter. Den store forskel er, at kunstige intelligenser ikke bare gør fysisk arbejde overflødig, de gør også vidensarbejde overflødigt.
I fremtiden kommer vi derfor til at se jobfunktioner, som bliver overtaget af kunstige intelligenser, og det interessante spørgsmål er så, hvordan virksomhederne håndterer denne overgang. Fyrer de bare hårdt og brutalt de overflødige medarbejdere, eller sørger de for omskoling, omrokering og hensynsfulde aftrædelsesordninger?
12. Skaber de kunstige intelligenser umenneskelige algoritmejobs?
Kunstige intelligenser er dygtige til at optimere processer. De kan finde den mest optimale rute for en lastbil, der skal levere varer, eller de kan kontrollere et logistikcenter, så robotter og mennesker fungerer i et optimalt flow, der ekspederer flest mulige pakker til verdens umættelige internetshoppere.
Problemet er bare, at de fleste af disse optimeringsprocesser sjældent foregår på medarbejdernes præmisser, hvilket resulterer i umenneskelige jobs, som man har set hos Amazon og nemlig.com, hvor medarbejdere må tisse i flasker og bliver trukket i løn, hvis de ikke kan følge robotternes og algoritmernes tempo. Gårsdagens mac-jobs er blevet til nutidens algoritmejobs.
Når kunstige intelligenser bliver sat til at optimere arbejdspladser, er det sjældent medarbejdernes trivsel, der står øverst på listen af prioriteter. Vi er nødt til at holde øje med og udfordre virksomhedernes brug af kunstige intelligenser og råbe vagt i gevær, når deres brug af kunstig intelligens kun handler om profit og ikke om trivsel.



























