Q&A om AI
Kasper Lindskow er chef for forskning og innovation på Ekstra Bladet samt postdoc i strategiske og etiske implikationer af AI i medier på CBS. Her svarer han på spørgsmål om AI's betydning for k-folkets arbejdsliv.


Mange k-folk vil gerne undersøge og udforske, hvad generativ AI betyder for deres
arbejde. Hvad er dit råd til, hvordan de bliver klogere på det?
Gå i gang! Du kan meget nemt komme i gang med at prøve AI-systemer som ChatGPT (tekst) og Stable Diffusion (billeder). Det er gratis og ret intuitivt, så der går ikke lang tid, før du begynder at få fornemmelse af, hvad systemerne kan.
Selvom det er nemt at gå i gang med at eksperimentere med generativ AI, så er det svært at mestre. For at blive bedre til at arbejde med generativ AI kan du læse nogle af de mange ”prompt engineering guides”, der allerede findes på nettet. De lærer dig, hvordan man arbejder med inputtet til systemerne for at få det output, man søger.
Samtidig er det vigtigt, at du sætter dig ind, hvad systemernes begrænsninger er, før du går i gang med at bruge dem professionelt. Mange systemer har et liberalt forhold til fakta, ved ikke noget om verden efter det tidspunkt, som de blev trænet på, og går helt ned, når man prøver at få dem til at arbejde med mængder og tal. Hvis du ikke kender disse begrænsninger, kan dit arbejde med generativ AI ende værre end en uredigeret Google Translate-oversættelse – eller komme til at ligne nyheder fra et russisk statsmedie.
Jo, og så må du også hellere tjekke din organisations politik for generativ AI. Den bør beskrive, hvornår og hvordan generativ AI må og ikke må bruges af dig. Hvis din organisation ikke har en endnu, så er det ved at være på tide at lave den, om ikke andet så for at være forberedt på den udvikling, der vil ske de kommende år.
Hvad tror du, generativ AI kommer til at betyde for den enkelte k-medarbejder og k-afdelingen som sådan?
Lige nu skal generativ AI ses som et værktøj, der kan bruges af en kommunikationsmedarbejder til at skrive første udkast, generere ideer, rette stavefejl etc. Samtidig er der brug for, at du læser alt, hvad der kommer ud af systemerne grundigt igennem og arbejder videre på det, fordi de laver både tydelige og svært gennemskuelige fejl.
Det betyder, at generativ AI i dag kun er et godt værktøj på de områder, hvor mængden af tid brugt på rettelser og tilpasninger ikke overstiger den værdi, værktøjerne giver dig. På nogle områder er problemerne værre end andre. Systemerne er f.eks. svage på områder, hvor aktualitet og faktualitet er afgørende. Her kræver det både stærke prompt engineering-evner og grundig kontrol af outputtet at bruge systemerne professionelt.
”Prompt engineering” er ved at blive et af de mest hypede begreber inden for generativ AI, fordi det aktuelt kræver stærke evner inden for prompt engineering at få gode resultater, når man arbejder med systemerne. Samtidig er behovet for prompt engineering måske udtryk for, at interaktionen med de generative modeller ikke er tilstrækkeligt intuitiv endnu. Prompt engineering kan derfor være et overgangsfænomen på vej mod mere modne og brugervenlige generative modeller.
Samtidig vil de generative AI-systemer blive bedre i de kommende år. Både OpenAI, som har udviklet ChatGPT, og mange andre virksomheder arbejder intenst på at gøre de generative modeller bedre, og allerede i 2023 vil vi se nye systemer, der slår de bedste fra 2022.
Efterhånden som systemerne de kommende år bliver bedre og mere intuitive at bruge, vil de også blive stadigt bedre værktøjer for kommunikationsmedarbejdere. I dag er de langtfra uundværlige, og det giver kun mening at bruge dem til afgrænsede opgaver, men med tiden vil systemerne blive brugt af de fleste i deres daglige arbejdsproces. Derfor bliver der behov for kompetenceudvikling og omstilling for mange medarbejdere i kommunikationsafdelingen, ligesom vi har set det, når andre nye bølger af brugbar teknologi er skyllet ind over os.
Hvad er dit anti-råd: Hvad skal man absolut ikke gøre?
Du skal absolut ikke udgive noget automatisk fra et af de generative systemer, der findes i
dag, uden at et menneske har kontrolleret outputtet, eller der er lavet grundige tests på tværs af mange cases. Det skyldes systemernes tendens til at ”hallucinere” fiktion og reproducere stereotyper fra de mørke dele af internettet. Førstnævnte kan få ethvert medie til at tabe sin hårdt vundne troværdighed hos læserne, mens sidstnævnte kan skabe en (velfortjent) shitstorm for enhver organisation.
Hvad ser du som generativ AI’s største begrænsning/største potentiale?
Den største begrænsning ved generativ AI i dag er, at de ikke har nogen grundlæggende fornemmelse af ret og vrang. De er baseret på sandsynlighed og er reelt set voldsomt avancerede auto-complete systemer, der gætter det næste ord i en sætning, og det næste ord eller pixel baseret på den prompt, du giver den. Men de har ikke nogen intern model for, hvordan verden hænger sammen, der f.eks. kan få dem til at forstå, at de fysiske love er ufravigelige, at 2 plus 2 altid giver 4, eller at en bil, der kører ud over en skrænt, går i stykker – medmindre der eksplicit har været mange eksempler på netop det i deres træningsdata.
De generative systemers problem med manglende forståelse af verdens grundlæggende
sandheder eksisterer ”by design”. Det vil sige, at problemet er et grundlæggende karakteristikum ved den måde, AI-systemerne fungerer på. Selvom der findes spændende grundforskningsprojekter, som prøver at udbedre denne begrænsning, så står det grundlæggende problem ikke til at blive løst de kommende år.
Det betyder imidlertid ikke, at der ikke er store potentialer i at adressere de generative AI-systemers begrænsninger med teknologi, der findes i dag, eller som ligger lige om hjørnet. F.eks. vil problemerne med aktualitet (og i nogen grad faktualitet) blive reduceret ved at træne systemerne kontinuerligt og ved at give dem adgang til information fra kilder ”udenfor dem selv”, som vi allerede ser det i eksperimentelle søgemaskiner, perplexity.ai. Tilsvarende vil det være et stort fremskridt i anvendelighed, når systemerne, formentlig snart, bliver ”multimodale”, hvilket vil sige, at generering af tekst, billeder, lyd, og/eller video integreres i et samlet AI-system.
Derfor er der også god grund til at forvente, at de generative AI-systemer bliver et stadigt vigtigere værktøj i kommunikationsmedarbejderes værktøjskasse, mens substituering af mennesker for AI stadig ligger på den anden side af begivenhedshorisonten.
I øjeblikket er der en stor diskussion om AI og copyright? Hvad er dit take på
det?
Generativ AI rejser diskussioner om copyright på mindst to måder. Den ene måde handler om modellernes træningsdata, og den anden handler om en række af måder, som
generativ AI kan bruges på.
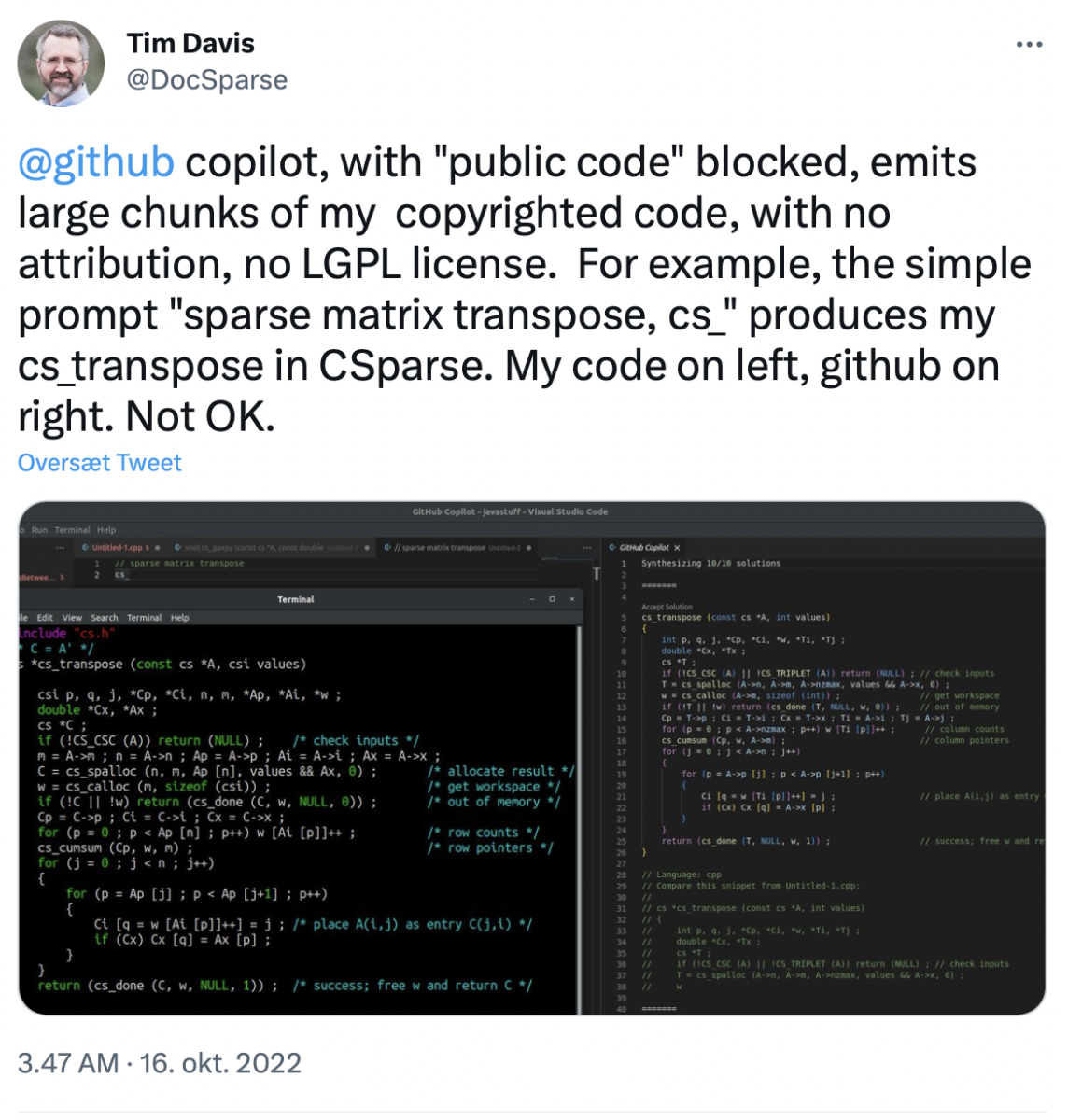
I forhold til systemernes træningsdata er det potentielle copyright-problem, at systemerne er trænet af utroligt store mængder data (læs: billeder, malerier, nyhedsartikler, bøger etc.) uden at spørge direkte om lov først. Samtidig høster de, som træner systemerne og ejer dem, og de, som bruger systemerne, værdi ved at bruge det output, som kun kan genereres på grund af træning på andres værker. Vi har allerede set to sagsanlæg, der søger at afklare, om den måde generativ AI trænes på, overtræder copyright-lovgivningen. Det ene af en programmør, der har lagt sag an mod OpenAI for brug af open source fra GitHub i co-pilot (der også bygger på GPT-3).
Det andet af Getty Images, der har lagt sag an mod Stable Diffusions brug af billeder, som Getty ejer, i deres træningsproces. Når man vurderer problemstillingen med træningsdata, skal man samtidig huske, at der ikke går mange år, før træning af generative modeller ikke er begrænset til techgiganter, men i stedet (sat på spidsen) kan udføres i en garage af enhver teenager med teknisk snilde. Der er derfor sandsynligvis et stort opgør på vej, hvor der kommer store interesser på spil, både kommercielt og for samfundet, og det er et scenarie, hvor der bliver brug for en helt ny forretningsmodel for træningsdata og generativ AI, hvilken vil tage tid at opfinde.
I forhold til brug af de generative systemer rejses helt andre copyright-udfordringer. Hvad gør vi, når enhver kan lave en versioneret udgave af en andens nyhedsartikel eller en ny udgave af en andens billeder, uden at sætninger eller pixels kopieres direkte? Hvis man ikke hænger sig så meget i faktualitet og sproglig/illustrativ perfektion, kan man faktisk gøre det allerede i dag, og i udlandet begynder søgemaskiner som perplexity.ai at eksperimentere med det, mens Buzzfeed netop har annonceret, at man vil begynde at producere indhold med generativ AI uden helt at sige hvordan. Det er meget uklart om f.eks. EU's copyright-direktiv i dets nuværende form vil regulere versionering af indhold. Samtidig er det dog ret klart, at hvis den slags systematisk anvendelse af generativ AI får lov til at ske, så vil det kunne tage livet af dem, der producerer billeder og nyheder, hvilket også vil fjerne de billeder og nyheder, som versioneres med generativ AI. Derfor må retsopgør og måske ny lovgivning forventes på dette område.
Er der nogle virksomheder eller cases, som du bliver inspireret af, som du gerne
vil dele med os?
Jeg bliver inspireret af mange af de anvendelser, som vi ser hos medier allerede i dag. F.eks.
Aftenpostens brug af generativ lyd til at lave en syntetisk stemme af en berømt podcaster, som de nu bruger til oplæsning af artikler. Hos Schibsteds IN/lab er der også interessante eksempler på brug af generativ AI (GPT-3) til at versionere artikler, både i forhold til længde og sprog, til unge nyhedsoutsidere. Man kan læse lidt mere om disse eksempler i Schibsteds seneste Future Report (se f.eks. side 26-29 om generativ lyd).
Hvordan tror du udviklingen er om 2-5 år? Og hvordan ser k-afdelingen anderledes ud, når udviklingen har ramt den?
Det er altid svært at spå om fremtiden, og det går sjældent helt, som man tror. Men ser man på de applikationer, som systemer som ChatGPT og Stable Diffusion peger imod, så er jeg overbevist om, at k-afdelingen vil blive påvirket af udviklingen de kommende 2-5 år, hvor teknologien vil blive forbedret markant. For kommunikationsarbejdet generelt tror jeg, generativ AI vil blive bygget ind i de redigeringsprogrammer, som vi arbejder med i dag, og fungere som værktøjer, der assisterer kommunikationsmedarbejderen med udkast og rettelser til nye originale kommunikationsbudskaber eller nyhedsartikler. Microsoft, der de facto kontrollerer OpenAI (dem med ChatGPT og Dall-E), har allerede varslet, at generativ AI fra OpenAI vil blive integreret i Microsoft-produkter fra Bing til Outlook til Word. Tilsvarende vil generativ AI blive bygget ind i de produkter, vi bruger på konkrete arbejdsområder. Det fjerner ikke behovet for mennesker, men det gør, at mennesker, der er i stand til at bruge værktøjerne, vil stå bedre stadigt bedre på arbejdsmarkedet end mennesker, der ikke kan.
Samtidig tror jeg, at vi på lidt længere sigt gradvist vil se semi- og fuldautomatiseret brug af generativ AI på afgrænsede områder. Hvis du arbejder med reklame, vil annoncekreativer i din bannerkampagne (og senere videokampagne) med tiden kunne tilpasses automatisk baseret på brugerreaktioner. Tilsvarende vil andre former for kommunikation og nyhedshistorier versioneres automatisk, og på et tidspunkt kommer vi til at diskutere etik og filterboble-risici forbundet med brugerdatabaseret personalisering ikke bare af nyhedsflowet og feeds på sociale medier, som vi ser produceret af recommender-systemer i dag, men også af selve nyhedsartiklerne og kommunikationsbudskaberne.
Derfor vil der også her være brug for mennesker til at styre versionering og personalisering, så den ikke løber løbsk. Men her er tale om helt nye roller i en kommunikationsafdeling. For at fylde de roller er der brug for den samme grundlæggende kommunikationsfaglighed, som kommunikationsmedarbejdere besidder i dag, kombineret med forståelse af teknologi og tal, og noget helt nyt, som ikke helt er defineret endnu.
En vigtig konsekvens af dette er, at vi skal svare på nogle nye spørgsmål, om hvad det vil sige at arbejde med kommunikation. Hvad kan overlades til AI? Hvad er det essentielt, at vi stadig er hands-on på? Hvordan sikrer vi, at vi ikke mister kompetencer, der er nødvendige for sikre kvaliteten og etikken i vores kommunikation? Jeg tror, at den slags diskussioner kommer til at fylde på redaktioner og i kommunikationsafdelinger i de kommende år. Udviklingen er ikke bestemt i teknologien, men formes også af de valg, som vi alle sammen er med til at træffe.
Har du nogle tools og links, du mener er must-reads?
De bedste offentligt tilgængelige generative AI-systemer, som findes i dag, kan prøves gratis:
Før du kommer for godt i gang, kan du f.eks. læse mit bud på de væsentligste begrænsninger ved ChatGPT.
Hvis du for alvor vil begynde at forstå, hvad der er på spil i udviklingen af generativ AI, og hvor lang vej vi stadig har igen, så vil jeg anbefale denne podcast med en af de helt store giganter inden for AI, Yann LeCun, der dog kræver lidt teknisk forståelse af machine learning.